
Data Observability: Why Context Is the Key to Trust
Your data isn’t broken, it’s just misunderstood.

In today’s data-driven world, we’re collecting more information than ever. But here’s the catch: data without context is just noise. You can have pipelines that run, dashboards that load, and models that train and still make the wrong decisions. Why? Because you’re missing the story behind the numbers.
This post explores why context is the foundation of trustworthy data, and how data observability helps restore confidence, speed, and clarity across your organization.
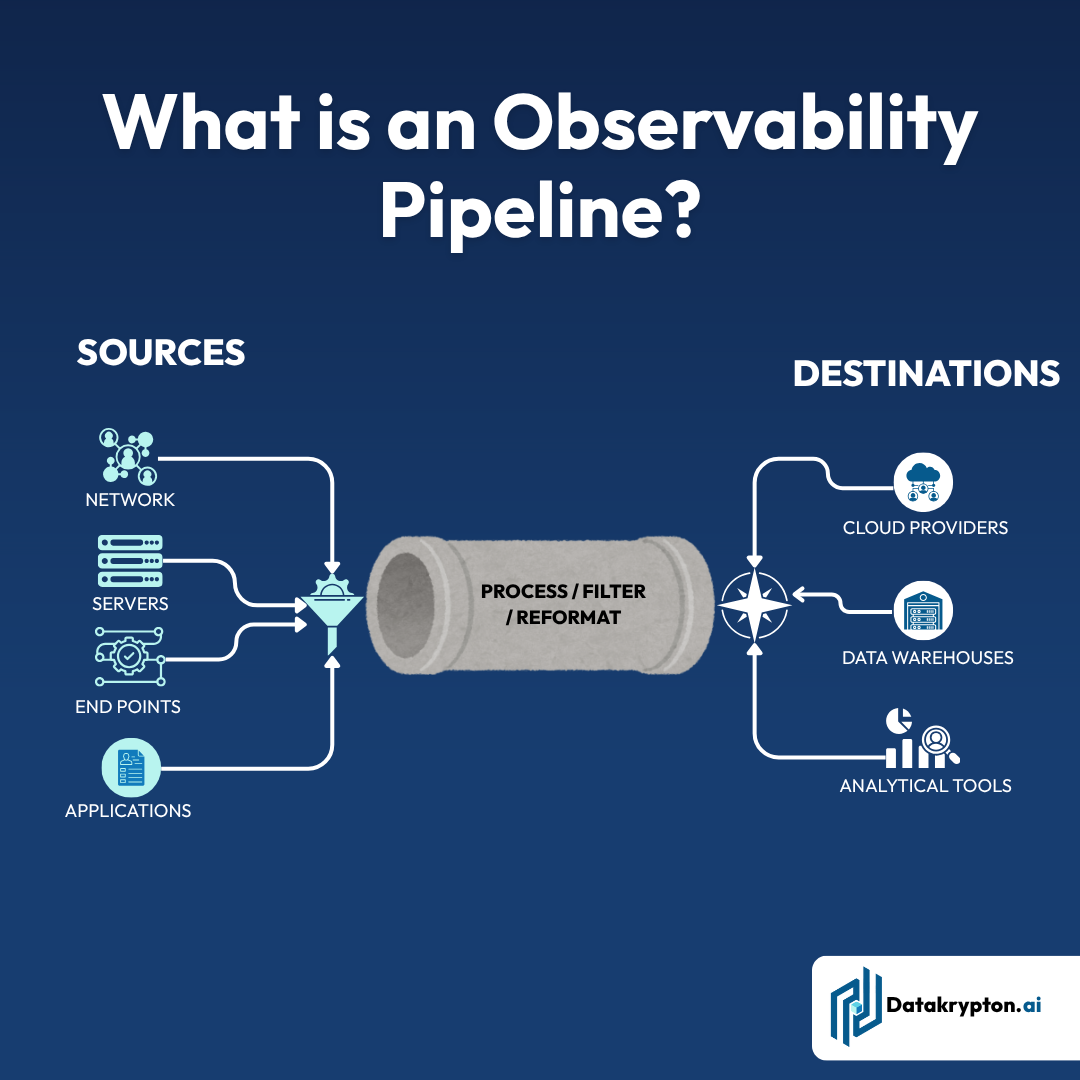
The Hidden Cost of Contextless Data
When data lacks lineage, freshness, or transformation history:
Executives act on outdated dashboards
Analysts chase phantom issues
Data scientists train models on corrupted inputs
The result? Data distrust. Users stop relying on dashboards and revert to gut instinct. Innovation slows. Compliance risks rise. And remediation becomes expensive.
Observability Starts with Understanding
Data observability isn’t just about alerts it’s about insight. It helps you answer:
Is the data fresh?
Did the schema change?
Are volumes consistent?
Where did this data come from?
Who depends on it downstream?
These questions aren’t just technical they’re strategic. When you embed context into observability, you unlock faster root-cause detection, better collaboration, and more reliable analytics and AI.

How to Build Context-Aware Observability
Start small. Pick one business-critical data flow and:
Map its context source, transformations, consumers
Track freshness, volume, schema, and lineage
Set alerts that include business impact
Automate anomaly detection and metadata capture
Measure outcomes trust regained, issues resolved faster, decisions made with confidence
Why It Matters for Analytics, ML & AI
Analytics: Dashboards need timely, accurate data.
ML/AI: Models trained on stale or broken data drift and mispredict.
Business agility: When users trust data, decisions accelerate.